
Scientists Surf Peptides with New POOL
December 17, 2018 | By Cynthia Dillon
Like surfers looking for the right waves for the right board, some chemists search for the right peptide for the right microstructure. “Peptide” is a perky sort of word that describes small proteins formed by amino acids that help our bodies function. In fitness, for example, they can help burn fat, build muscle and improve performance. In skincare, they can energize collagen synthesis and bolster keratin and elastin. And in science, their wonders could be ceaseless, which is why a group of researchers is interested in finding the right set of peptides needed to synthesize them—a custom-made peptide could act as a drug delivered with specificity within the body, or it could be used to discover unknown DNA sequences.
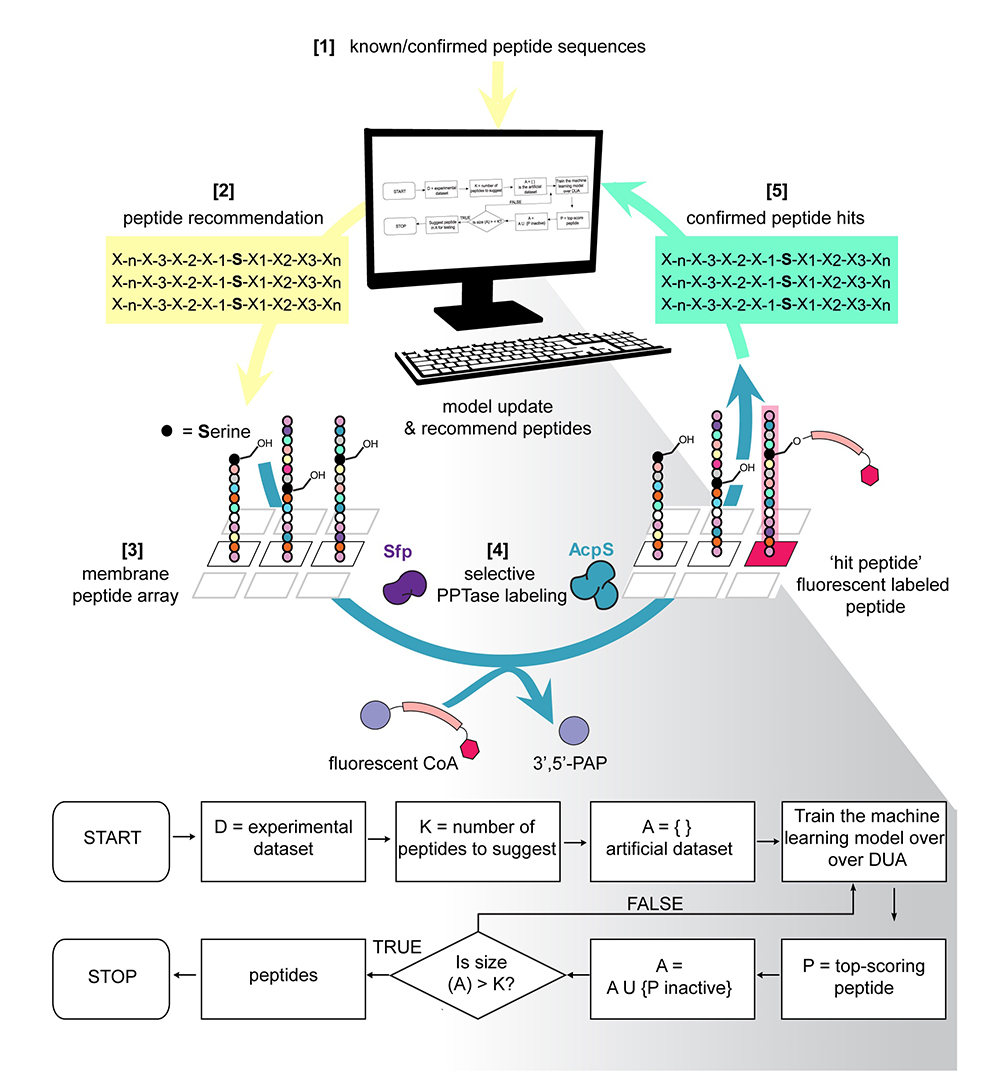
Now such possibilities are closer to reality through the work of UC San Diego Professor Michael Burkart and student researchers Lorillee Tallorin and Woojoo Eunice Kim. In a paper recently published in Nature Communications, Burkart, an expert in biological chemistry and enzymology; Kim, a graduate student in the Department of Chemistry and Biochemistry and Tallorin, a former UC San Diego graduate student—along with colleagues Nathan Gianneschi (Northwestern), Peter Frazier (Cornell) and Mike Gilson (UC San Diego’s Skaggs School of Pharmacy and Pharmaceutical Sciences)—describe their methodology for creating peptides that could produce biomaterials, like nanostructures and microstructures, to modify proteins.
First, the scientists had to identify certain peptides that could act as enzyme substrates for such outcomes, which is time-consuming. To save time, they developed a new process for finding the right peptide sequences by using a machine-learning, computer algorithm named Peptide Optimization with Optimal Learning (POOL). The algorithm analyzed experimental data and offered suggestions on the next best sequences to test, streamlining the path to finding the most efficient peptide substrates for the enzyme. This new approach could provide a new framework for future experiments across materials science and chemistry.
According to Burkart, the ability to rapidly select ideal substrates or binding partners in this way opens the door to numerous real-world applications, such as the rapid development of diagnostics against viral outbreaks or the rapid design of medicines.
“Practically speaking, it can save a wide variety of researchers time and money,” said Burkart. “This methodology allowed us to avoid expensive robots and instead utilize a benchtop peptide synthesizer to create our libraries. The machine learning algorithm enabled us to iterate the process in only a few rounds and arrive at highly specific peptide substrates.”
Burkart and Gianneschi trained the algorithm designed by Frazier and used it to develop a lineup of promising peptides, experimenting with them until they found the most effective. Then they loaded that information into the algorithm, which recommended both changes for the next round of peptide development and strategies predicted to fail.
“Now we were starting to get selectivity,” Gianneschi said. “Instead of guessing and looking at millions of peptides, we were able to look at hundreds of peptides and very quickly converge on sequences that behaved in completely new ways.”
According to the scientists, when compared to random mutations or guesswork, the algorithm method was statistically more successful. And, although this research focused on substrates, the process could be used to discover peptides for various other purposes. The next step will be to automate the entire process.
“This POOL methodology can be applied to identify biologically active peptide substrates important for epitope mapping, antigen discovery and receptors,” noted Kim. “The new peptide substrates recommended by POOL guide us to explore broader chemical space and, furthermore, can be utilized to search for multiple features of the enzyme substrates at the same time.”
This work was supported by the U.S. Air Force (AFOSR grants FA9550-12-1-0414, FA9550-12-1-0200 and FA9550-16-1-0046), The National Institutes of Health (grants R01 GM095970 and F31GM113470) and the National Science Foundation (grants IOS1516156 and DMR-182242).
News Contact
Cynthia Dillon
(858) 822-0142